An interesting thing occurred last weekend on Sunday morning. Really, really early. A leap second was applied to Coordinated Universal Time (UTC) and Linux admins everywhere were suddenly awakened as their servers started pegging CPU's and setting off alarms. Oops. Looks like there is a bug in the current Linux kernel that caused a bit of havoc. You can read all about it, but I'll leave understanding the details of the bug as an exercise for those of you that are interested in those kinds of things.
Unfortunately this bug affected our video streaming servers and I was one of those lucky admins that woke up Sunday morning wondering what was going on. Specifically, our server in Europe was raising flags as it had become unresponsive and couldn't be pinged, likely meaning it was also not serving video to our customers. Yuck. Luckily for us the fix was pretty easy. Stop NTP, set the date, and restart NTP. And then I went about the rest of my Sunday figuring I would keep an eye on it and do a more in-depth investigation on Monday morning when I a.) had more time, and b.) had the brain's of a few others to help me figure out what was going on.
What was really cool about all of this, was that Monday morning I was able to load up our Zabbix application, dig in to all of our various edge servers, and try to see what was going on. This is something that we wouldn't have been able to do on our own, prior to our switch to EC2/Wowza for streaming videos. I was surprised to see the following CPU load:
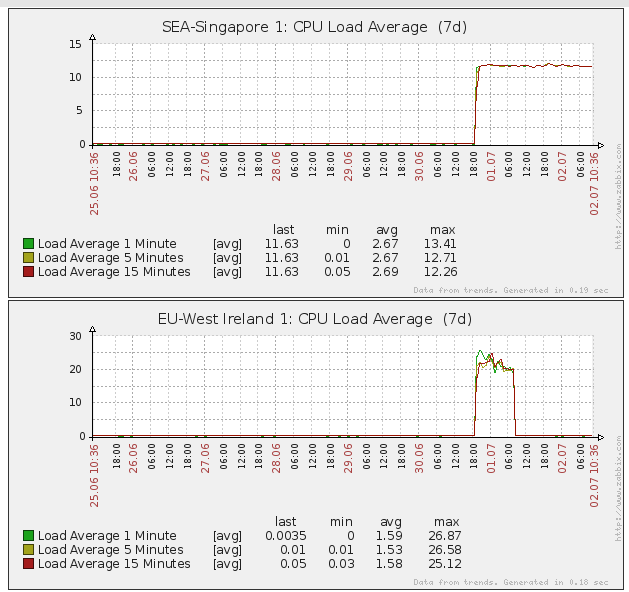
In the graph above, you'll see the average load for two of our servers. The EU one was the one that had become unresponsive, and was subsequently restarted. The other one is a server in Singapore that had not been restarted/fixed and was still pegging the CPU, though was continuing to serve video. I do suspect, however, that the video watching experience was pretty poor for those users during that time.
We've since gone through and updated all of our servers and made sure that they are responding within normal ranges. It's exciting to have this level of transparency into what is going on with each of our video servers. Yes, it totally means more work on our end as we were the ones that had to find and fix that problem. However it's nice to know that we can do it ourselves rather than having to wait with our hands tied behind our backs for someone else to fix the problem.
I'm sure we'll have more thoughts about running our own streaming video service in the future now that we have fun graphs to share. And if you're running any Linux servers make sure you've checked your CPU load after last weekends leap second to make sure everything is running normally.
There's a lot more info about all of this here for anyone else that may have been affected.
Add new comment